Jevons Paradox and the Future of SRE
What the SRE role looks like today, next quarter, and one year from now.

The Paradox of Efficiency
In 1865, William Stanley Jevons observed a counterintuitive trend: as steam engines became more fuel-efficient, total coal consumption increased. The efficiency didn't save resources; it unlocked new use cases, and demand expanded to fill the void.
Aaron Levie, CEO of Box, applied this logic to AI and knowledge work including software engineering. He argued that most AI tokens will be spent creating software that doesn't exist yet. If AI makes writing code 10x more efficient, we won't simply build the same apps with fewer people. We will attempt to build systems that are 10x more complex. This aligns with recent results from Lenny’s analysis, which shows that despite AI's rise, demand for software engineers continues to climb as the ceiling for complexity rises.
This pattern applies directly to SRE. Historically, proactive reliability work that prevents incidents before they happen has been pushed to the bottom of the backlog. Why? Because the toil of on-call triage and incident investigations consumed every available hour. When AI absorbs that toil, the result isn't a smaller SRE team. It’s an SRE team finally empowered to tackle the previously infeasible backlog of deep reliability engineering.
The Collapse of the Silo
Yoni Rechtman, VC at Slow Ventures, is predicting a more precise endpoint, arguing the only jobs that survive inside AI-native companies collapse into four clusters.
The Product Engineer: Vibe-codes features and owns commercial outcomes.
The SRE/Infra/Security Engineer: Stitches output into something stable and secure.
The Adult: Acts as a governor of an accelerating organization.
The Human Surface: Manages the interface from Sales to CX.
Let's look at this from the lens of a mid to large enterprise with 1000+ engineers that wants to become AI native over the next few quarters. Such an enterprise already sees Cluster 1 emerge as an overlap of Frontend Developer + PM + UX Designer. Cluster 2 will emerge next as the logical overlap between the Backend Developer and the SRE/Infra Engineer, with the SRE side also absorbing Cluster 3. I feel these roles are moving toward a model where they operate as a single team, distinguished only by their focus on Breadth versus Depth, with the Depth side additionally serving as the organizational governor. More on this in Phase 3.
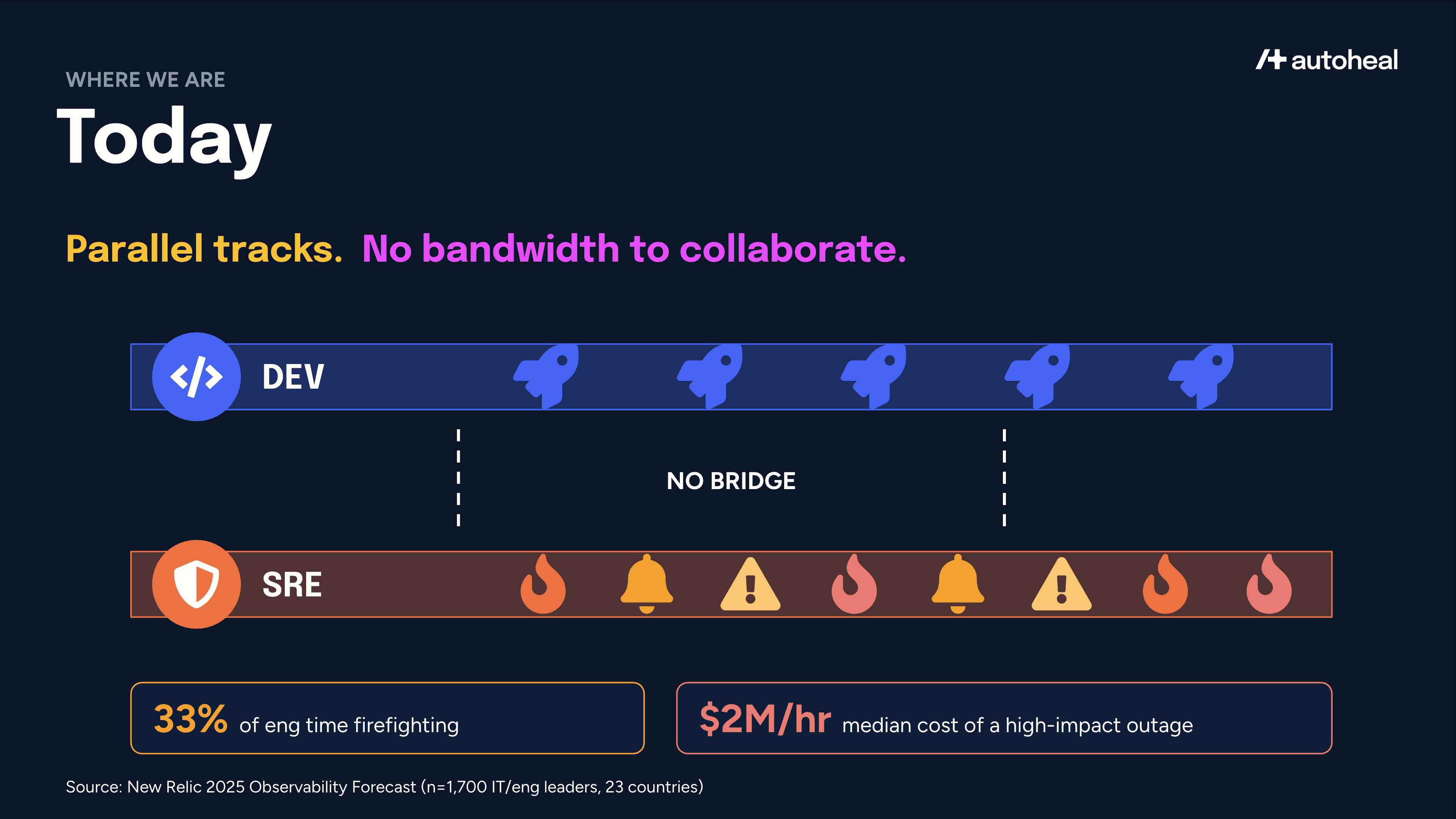
Phase 1: Today – Parallel Tracks
Today at mid to large enterprises, Dev and SRE run on parallel tracks with no real bridge between them. Devs write features and SREs maintain them. According to the New Relic 2025 Observability Forecast, 33% of engineering time is lost to firefighting, and a single high-impact outage costs a median of $2M per hour. As a result, collaboration is usually reactive and limited to postmortems after the damage is done. SREs have the expertise to provide design guidance, but they simply lack the cycles to engage.
Phase 2: Next Quarter – Meeting in the Middle
AI reduces the cost of the mechanical SRE layer, which is alert triage, incident investigations, root cause investigations, runbook execution, postmortem analysis, and preventive fixes. When this cost falls, Jevons kicks in and demand for high-judgment reliability work expands.
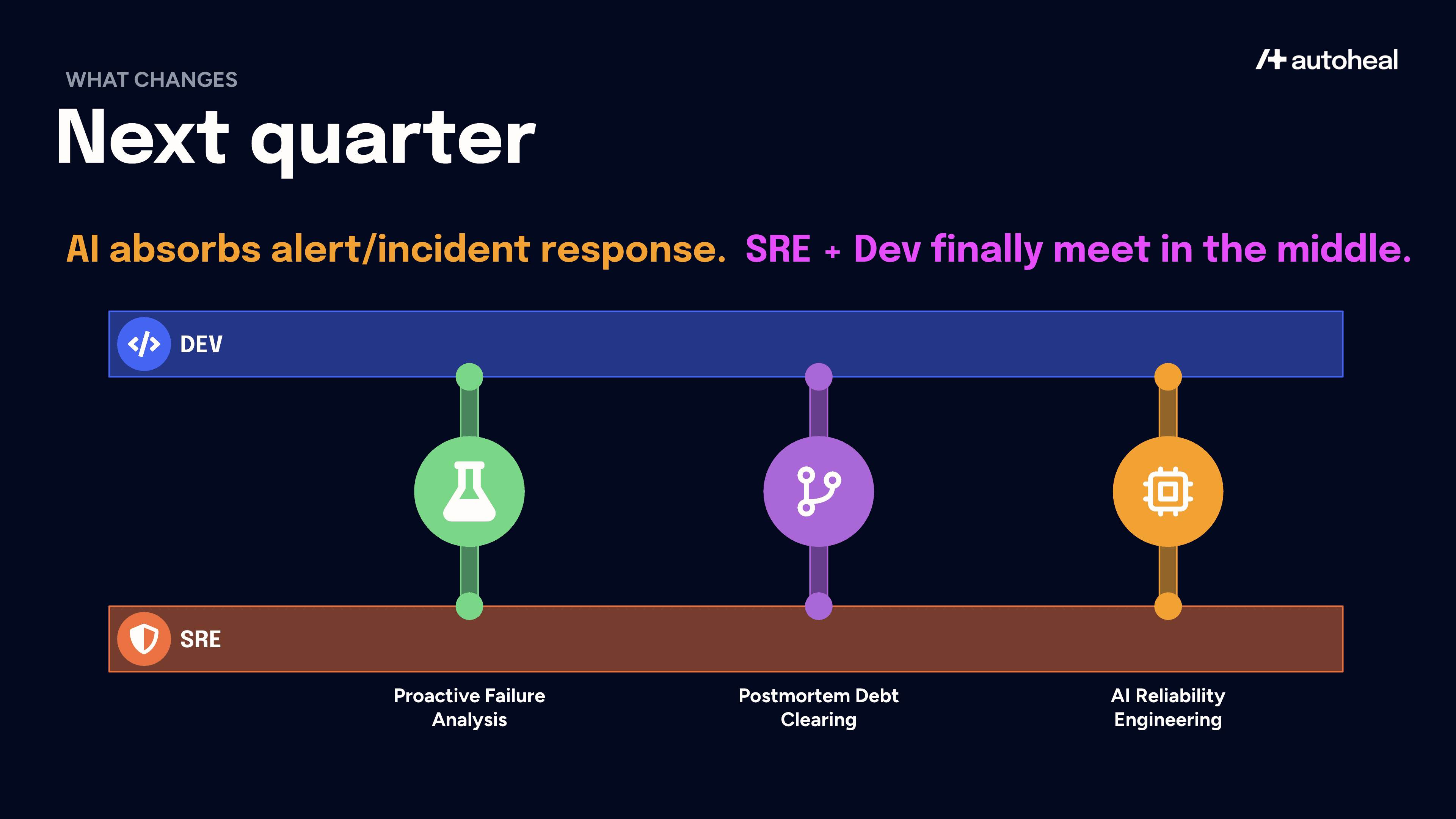
Three places I expect Dev and SRE to start meeting in the middle for enterprises that embrace AI not just for coding but also for production engineering.
1. Proactive Failure Analysis
AI will transform SRE practices by enhancing chaos engineering beyond known failures. By analyzing architecture and incident data, AI will suggest novel failure hypotheses, which SREs will bring to development teams for fixing. Furthermore, AI will convert SRE's unwritten tribal knowledge, such as incident patterns, into automated production guardrails like incident-driven regression tests. Gartner predicts that 75% of organizations will integrate AI-distilled SRE lessons into product design by 2029, a significant increase from 10% in 2025.
2. Postmortem Debt Clearing
Every engineering org has a graveyard of incidents that were technically resolved but never got a real postmortem. As the Google SRE book puts it, the value of a postmortem is proportional to the learning it creates, which is why the orgs that keep investing in postmortem culture weather fewer outages and recover faster when novel failures do land. When AI surfaces contributing factors in minutes and proposes actionable preventive fixes, the backlog becomes tractable, and the architectural lesson stops living in one person's head.
3. AI Reliability Engineering
The introduction of AI agents and ML models into production brings non-deterministic failure modes. These include subtle model drifts that bypass typical alerts, context rot that are hard to model via threshold-based alerts, and SLOs that must now incorporate model confidence alongside latency. Additionally, SREs will need to ensure the underlying automation tools are reliable and operate correctly, which is a new domain of AI-as-Infrastructure. Since playbooks for these issues are still being written, development teams deploying AI/ML features require an SRE partner to custom design their reliability infrastructure.
A note for enterprises under SOC 2, SOX, HIPAA, or PCI: the Jevons unlock applies just as directly, but adoption will sequence through a governance ladder. AI production engineering agents must deploy inside the VPC or on-prem so that logs, runbooks, and incident data never leave the boundary. Rollout follows a familiar risk curve of observing, then suggesting, then taking scoped actions, with each step passing the same change-approval and segregation-of-duties controls production already runs through. SRE teams that have applied this discipline to traditional automation for years are uniquely positioned to apply it to AI.
Phase 3: Next Year – Breadth vs. Depth
At AI-native companies, coding agents now touch nearly every merged pull request, and even in regulated enterprises where adoption is more cautious, Dev bandwidth gains from AI-assisted coding and review are already measurable. At the same time, AI production engineering agents are starting to tackle alert and incident investigations, freeing up SREs. The next step is for these two agents to collaborate on preventive fixes that update regression tests, observability config as well as CI/CD governance policies.
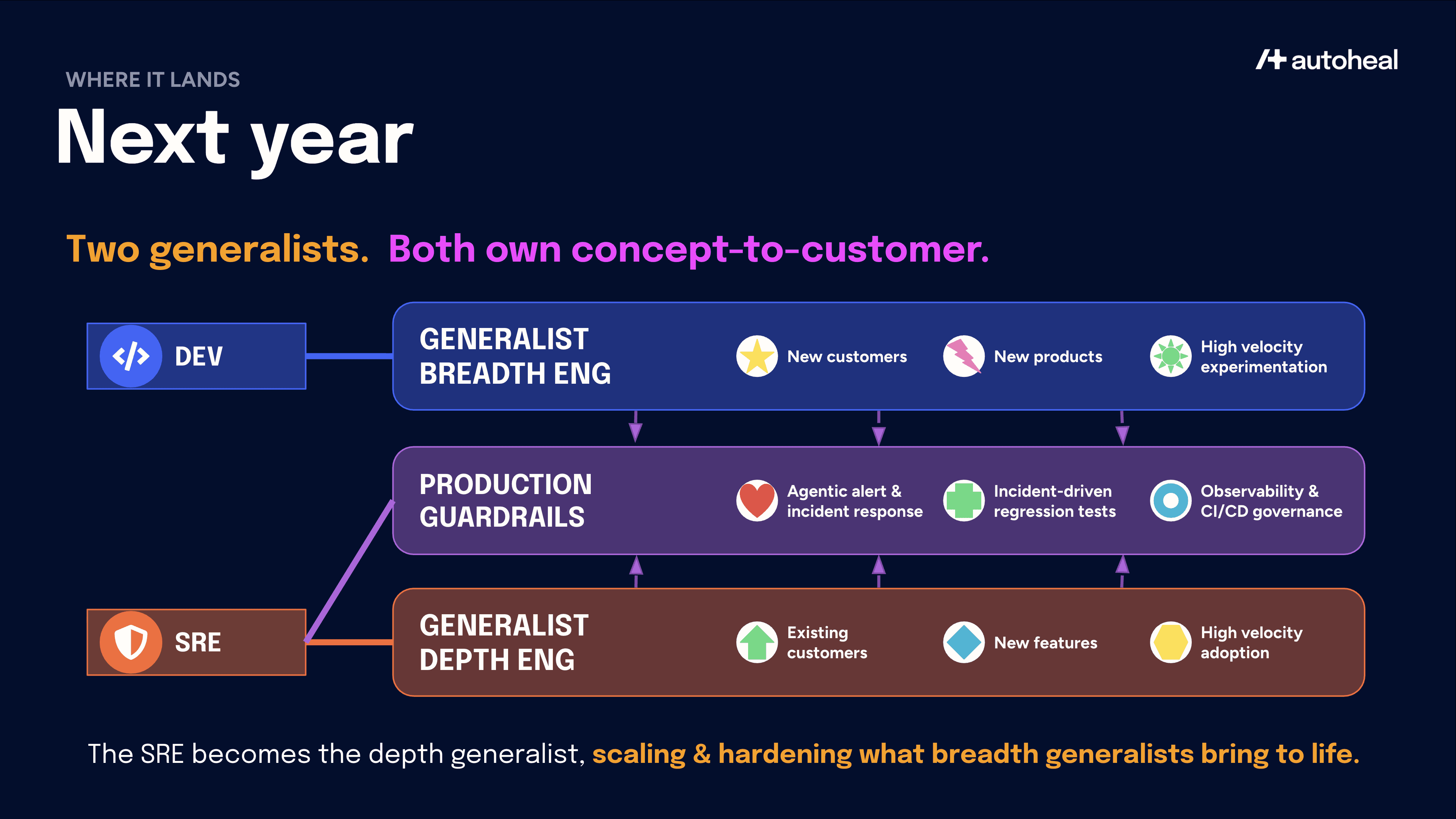
When used in such a combination, the SRE bandwidth obstacle is removed and the traditionally separate Dev and SRE roles compress into something new, but not into a single archetype. They split along the axis of business motion into two kinds of generalist, both of whom own concept-to-customer outcomes end-to-end rather than handing off at every stage.
The Generalist Breadth Engineer (formerly Dev): Focuses on new customer acquisition via new products and high-velocity experiments. They now own production engineering by leveraging the production guardrails owned and operated by the depth engineer to keep their applications safe. The end result is new business acceleration via elimination of the specialist handoff. This role fits Yoni’s 'Product Engineer' cluster above.
The Generalist Depth Engineer (formerly SRE): Focuses on accelerating feature adoption at existing customers by hardening and scaling systems. This is a high-agency role that now goes beyond production engineering. With coding agents at their disposal, they don't just recommend fixes but go all the way to implement them directly. This role also absorbs the 'Adult' cluster from earlier. They become the governor of an accelerating organization, the role that ensures velocity does not turn into instability.
The above shift has been live in Infrastructure-as-Code for more than a decade and is now coming to customer-facing applications. The depth engineer role will not be limited to SREs. It will also encompass other backend developers who are today building shared platform services for product engineers such as authentication/authorization, data infrastructure & analytics, app security and more.
This shift undoubtedly requires overcoming significant organizational friction in established enterprises, specifically resistance to eliminating the specialist handoff and integrating historically separate budget and reporting structures. However, leaders who understand the potential of AI-native transformation powered by end-to-end ownership will take this friction head on in the next few quarters.
Note that this shift is distinctly different from the failed "everyone owns operations" experiment of the 2010s. Cognitive load overwhelmed developers and production specialization via SRE was the only way out at that time. Now, AI production engineering agents can carry the operational context (failure history, alert thresholds, experts’ decision traces) that developers cannot. This shift from bounded human memory to infinite institutional memory enables generalist engineers to operate effectively.
What does this mean for SREs?
If you as an SRE spent the last few years building a real model of how your systems fail and where customers actually get hurt, you are holding one of the most valuable assets in engineering right now. Expanding your role into the depth track is the natural next step. Your new skills portfolio needs to include expertise in advanced systems architecture for non-deterministic environments, AI reliability engineering and deep platform knowledge to rollout the AI production engineering agents across the entire engineering org. You have the opportunity to become the primary driver of transformation of your company into its AI-native incarnation.
