Reliability is Now a Functional Requirement
The term 'non-functional' was a compromise from a simpler time. Today, with the arrival of AI tooling and enforceable regulation like DORA, this compromise is a liability. Reliability has to become an inseparable, measurable, and auditable part of the system's core behavior.


New Relic’s 2025 Observability Forecast reports the median business loses $76M per year to high-impact outages, at a cost of $2M per hour. 33% of engineering hours go to fighting fires or addressing disruptions. Yet, we still treat Reliability, the lifeblood of our systems, like a footnote. This is because we continue to rely on a 4-decade old abstraction: Developers ship, SREs firefight and they get together quarterly to audit the consequences.
This approach traces back to IEEE SRS and ISO/IEC software quality standards that split requirements into two buckets: functional (what the system does) and non-functional (how well it does it). Reliability landed in the second bucket alongside security. The name ‘non-functional’ gave us the permission to treat it as a secondary event that can be figured out later.
Why we lived with the broken loop
The broken loop between developers & SRE was a pragmatic response to three insurmountable technical constraints that made proactive reliability nearly impossible. Engineering organizations compensated for these constraints by creating shift-left linters, best practice Confluence docs and a release checklist culture. SRE teams stayed underwater unfortunately.

Test Case Gap
Unknown failure modes could not be written as test cases in advance. Especially when multiple services are doing normal things but the combination becomes a failure.
Test Data Gap
Production data’s format, volume, and velocity could never be meaningfully reproduced. A system stable against 10GB of sanitized data might buckle under 10TB of real traffic with unexpected field values and burst patterns.
Test Environment Gap
Staging could not match production configs, whether due to cost or lack of IaC standardization. Passing tests in staging guaranteed little about production behavior.
How AI is strengthening prevention over reaction
AI gives SREs a force multiplier without adding headcount. Every alert, incident, and near-miss becomes structured institutional knowledge pushed upstream in real time. Gartner’s inaugural Market Guide for AI SRE Tooling (Jan 2026) predicts 85% of enterprises will use such tooling by 2029 (up from <5% today), with 75% integrating AI-distilled lessons directly into product design. This shift directly removes the three constraints we discussed earlier.
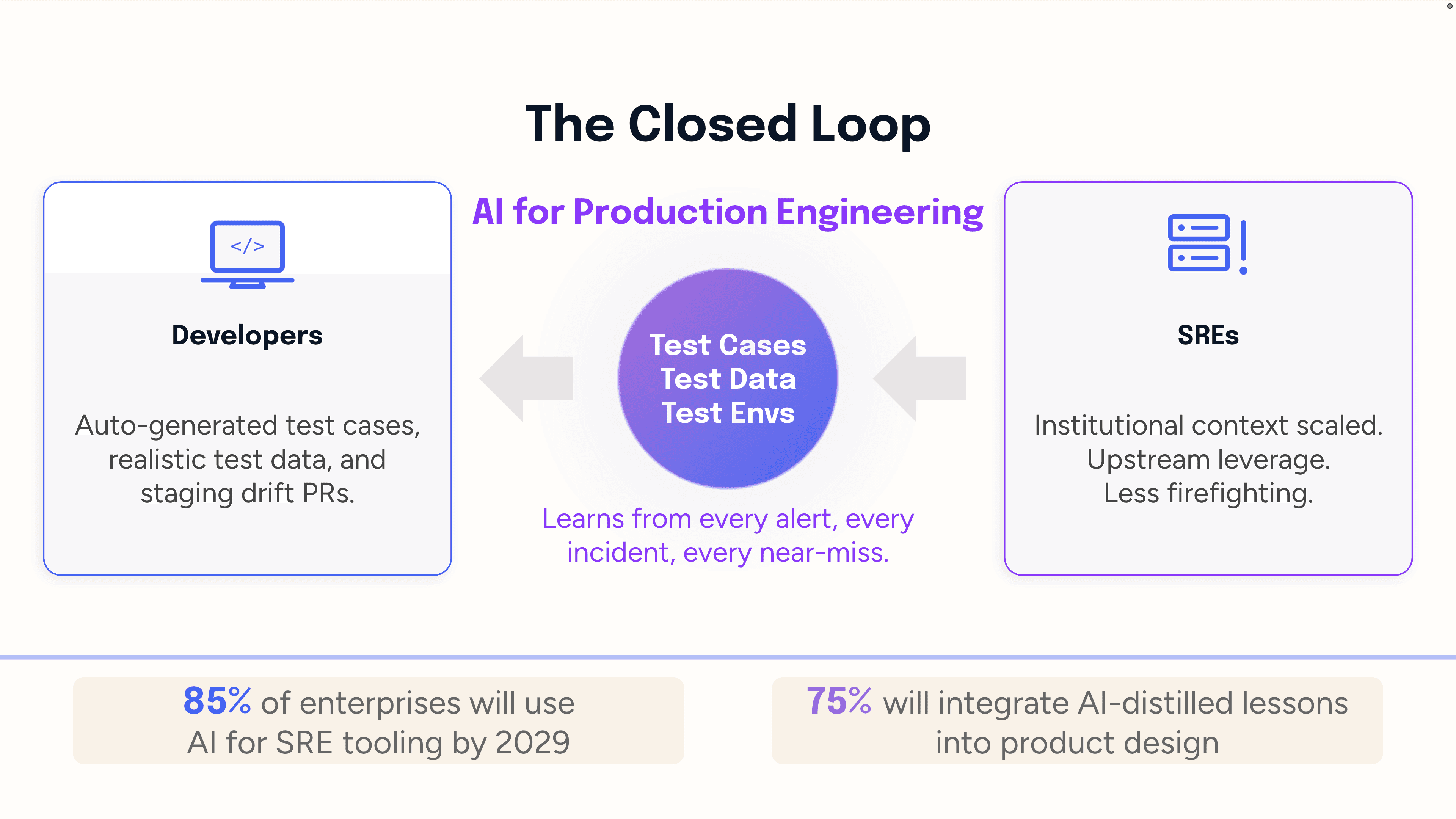
Closing the Test Case Gap
An agent mines alert and incident data, which act as undocumented test cases, to extract the exact conditions (service combinations, timing, load) that caused real failures and auto-generate tests. This catches emergent failures, such as cascade failures from complex interactions, that isolated development testing misses. It also identifies weak production telemetry signals that precede incidents, generating tests for failure modes before they fully materialize.
Closing the Test Data Gap
Sanitized test data lacks the "weirdness" of production which includes unexpected values, malformed inputs, and burst patterns. An agent with deep production knowledge can generate statistically realistic synthetic data that mirrors the true distribution, velocity, and anomaly rate of real traffic, without exposing sensitive information. This stress-tests systems against what real traffic actually looks like, unlike clean, low-volume test data.
Closing the Test Environment Gap
Staging fails due to configuration drift and cost-cutting. An agent can prevent this by continuously comparing staging and production configurations, identifying differences (e.g., missing environment variables, IaC gaps), and auto-generating PRs to fix them pre-deployment. It also establishes a live production behavior baseline, flagging any staging deployment that deviates in ways historically linked to incidents. Staging thus becomes a reliable validation step, not a hopeful guess.
Why reliability matters most in regulated enterprises
Reliability is critical for regulated enterprises like banks, fintechs, healthcare due to 4 core factors:
Regulatory Mandates & Fines (e.g., DORA, HIPAA) enforce operational resilience, penalizing failure.
Reputational & Trust Damage occurs instantly with outages, especially when essential services (finance, patient care) are impacted
Data Sensitivity links reliability to security, as system failures risk compounding sensitive data breaches.
Audit & Traceability Requirements mandate systematic, documented proof of compliance, requiring formalized resolution.
The new mandate: Reliability as a core functional requirement
The term 'non-functional' was a compromise from a simpler time. Today, with the arrival of AI tooling and enforceable regulation like DORA, this compromise is a liability. Reliability can no longer be an afterthought; it has to become an inseparable, measurable, and auditable part of the system's core behavior. The teams that stop treating it as 'non-functional' are the ones who will deliver unbreakable customer experiences.
