Why Senior SREs Distrust AI SRE
A Path Forward: Delivering Value with AI for Production Engineering

I spent the last 9 months talking to some of the most experienced SREs in the industry. Staff engineers at fintechs, platform leads at regulated enterprises, battle-hardened engineers who have kept critical systems running for a decade.
Almost all of them were skeptical of "AI SRE" tools. Their leaders, meanwhile, were excited about the promise. To understand this disconnect we have to understand what the job actually is and where AI can help.
The Naming Problem
Part of the distrust comes from the name “AI SRE”. It was coined by early startups in 2024 who needed a punchy label for venture pitches. “AI agent that automates tasks for Site Reliability Engineers” became “AI SRE”. Gartner formalized it in their 2025 Hype Cycle as well as Jan 2026 Market Guide for AI SRE Tooling. Enterprise buyers started putting it in RFPs and the name rippled through management chains before anyone thought about how a senior engineer would perceive it.
The problem is that "SRE" refers to both the person and the practice. When a vendor pitches an "AI SRE", an experienced practitioner hears, "We are replacing you". This is true even when the product’s actual goal is to automate the daily toil that keeps engineers from high-value proactive work. The name made the category attractive to investors but at the expense of alienating the users whose adoption is necessary for success.
The Hallucination Problem
Production context is fragmented across dozens of systems: your observability stack, your cloud platform, your incident management tools, a Slack thread from eight months ago, a runbook someone wrote after a 2 AM incident but never updated, and the mental model of the one engineer who has touched that service for three years. Any AI tool claiming to reason across all of that is either oversimplifying or hallucinating. In reality, engineers have been burned by a confident AI conclusion that missed the context only Sarah on the SRE team gained over years of experience in incident response.
The Chatbot Problem
The Google SRE book defined the role as what happens when you ask a software engineer to design an operations function. SREs write code to eliminate toil, own service level objectives, manage error budgets, and design systems that increase reliability and feature velocity simultaneously. This means not just handling alert/incident response during on-call but also periodic tasks like capacity planning, resilience/DR testing, cloud cost management and more. The book recommends capping on-call toil at 50% of an SRE’s time, specifically so the other 50% goes to proactive engineering work.
Experienced SREs were largely unconvinced by early AI SRE tools because the technology was primarily limited to a Retrieval-Augmented Generation (RAG) chatbot. While these bots could search documentation and observability data during an incident, they lacked the authority and agency to perform high-value tasks autonomously while remaining under SRE supervision. Crucially, they failed to automate repetitive on-call duties, such as alert triage and incident investigations, and did not proactively enhance production resilience via actions like auto-generating preventive fixes from postmortems.
The Governance Problem
Then there is the security and governance concern, which is entirely rational at large enterprises. Early AI SRE tools required broad read access across production systems and could run unbounded queries against them. That is a real operational risk because unbounded queries can bring down production, and the CISO organization rightly saw the AI SRE itself as a new attack surface. In regulated industries, that is a compliance question with real legal exposure. Most early tools had no credible answer to it. No access controls worth scrutinizing, no audit framework for explaining to a security engineer or a regulator what the agent did and why. For a senior SRE at a bank or a healthcare platform, skepticism was the natural outcome.
Late 2025 Changed the Equation
Most of the skepticism in this space was earned between 2024 and mid-2025, when AI SRE vendors were building on LLMs that could not do what the pitch decks claimed. Context windows were too small. Multi-step agentic reasoning either did not exist or degraded badly under real production complexity, especially on the first generation of reasoning models. The tools failed not because the category was wrong, but because the underlying models were not ready. Vendors overpromised, customers got burned, and the skepticism hardened into something that feels like principle but is really scar tissue from a specific window in time.
In November 2025 after the release of Claude Opus 4.5, extended context handling crossed a threshold which enabled a step function upgrade on what was possible. Models went from losing coherence after a few reasoning steps to sustaining multi-hypothesis investigation across hundreds of thousands of tokens of production context. The practical difference: an AI agent could now hold a service dependency graph, three weeks of deployment history, and a set of conflicting observability signals in working memory at the same time, and reason across them without hallucinating connections that were not there.
AI capabilities are rapidly advancing in April 2026 with the preview launch of Claude Mythos yesterday. Anthropic’s internal benchmarks show Mythos offers a 12–15% increase in coding, reasoning, and cybersecurity, providing a step function jump in the power of current models. This means the environment that created past distrust is no longer the same.
What Other Verticals Figured Out
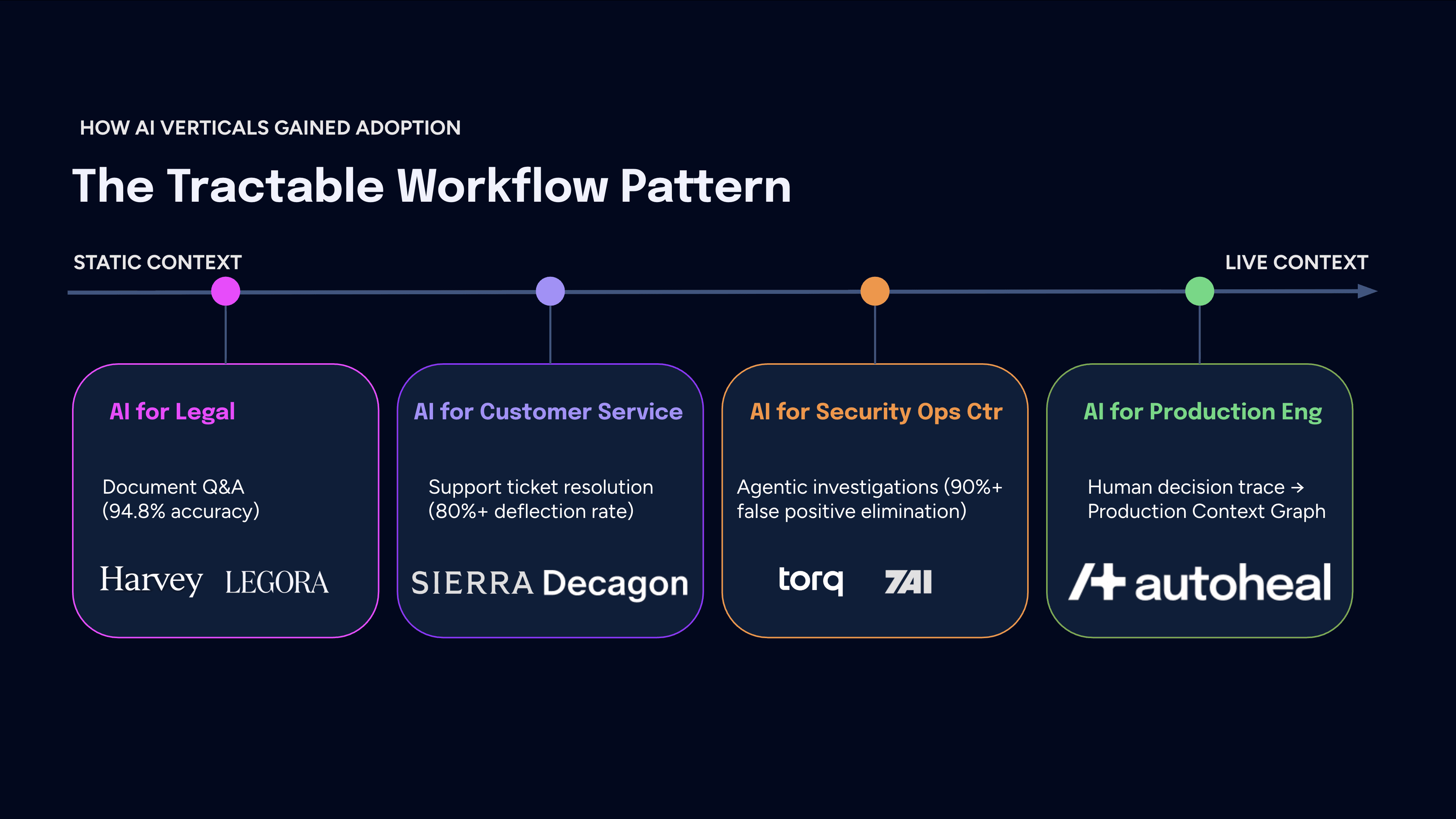
The skeptics assume that because AI cannot handle full production context, the category cannot deliver. But three other verticals faced the same fragmented-context problem and found a way through it. The pattern was the same in each case: stop trying to solve context fragmentation in the abstract, find the Tractable Workflow where AI can deliver hard ROI today, and leave human judgment intact for the rest.
AI for Legal: context is fragmented across thousands of documents, jurisdiction-specific precedent, and institutional knowledge about how a counterparty negotiates. The tractable workflow was a document Q&A. Harvey hit 94.8% accuracy there (versus 80.2% on tasks requiring reasoning across longer, fragmented contexts) and became an $8B company. Lawyers stayed in the loop for the rest.
AI for Customer Service: context is fragmented across CRM history, prior tickets, product state, and account data in disconnected systems. The tractable workflow was customer support ticket resolution. Sierra and Decagon built agents scoped to that workflow, priced on outcomes, and delivered ROI that was measurable in the form of 80%+ deflection rates.
AI for Security Operations Center: context is fragmented across SIEM, EDR, network logs, identity systems, and cloud infrastructure, and unlike legal or customer service, it is live and volatile. The tractable workflow was the alert-to-resolution process. Startups like Torq and 7AI are starting to give SOC analysts 50% of their time back through 90%+ false positive elimination.
All three verticals prove that you need to find the right tractable workflow. Crucially, none have yet taken the next step of compounding the decision traces from each task into reusable institutional memory. That is where the SRE opportunity lies.
The Tractable Workflow in SRE
Production context is live. It compounds, degrades, and gets invalidated by every change that goes in. The environment your AI reasoned about yesterday may not be the one you are debugging today. The missing piece of this puzzle is the human decision trace: the reasoning a senior engineer applies between the moment an alert fires and the moment the incident closes. That sequence of decisions (what they checked first, what they ruled out, why they went left instead of right) already solved the context problem once. It contains the institutional knowledge that no telemetry pipeline can capture. The question is whether we captured it so the next engineer, or an agent, can use it again.
Without capturing this, teams suffer from institutional amnesia, solving the same problems from scratch every few weeks.
Now Is the Time to Regain Trust
Rejecting AI SRE because tools from 2024 could not handle full production context was a reasonable response to the tools that existed then. The models have leapfrogged and the best ones are still accelerating. The right question today is not whether AI can handle full production context, but whether we have identified the tractable workflow where it can compound real value and capture the human decisions that fill the gap.
The path to earning trust starts with a reframe. We are not building an "AI SRE". Instead, we are building AI for Production Engineering.
At Autoheal, we focus on the on-call toil first. Our agents handle the initial alert response with fast investigations to separate noise from signal. High-signal alerts escalate to deep investigations involving multi-hypothesis root cause analysis and adversarial verification.
When an investigation requires human expertise, the system escalates to incidents via Slack-native Incident Response and paging the engineers. How engineers reason and collaborate through resolution is fully instrumented. Every one of those interactions produces a decision trace that feeds the Production Context Graph, which becomes the reasoning anchor for the next alert or incident.

This approach bypasses the need for upfront context resolution by compounding institutional memory from every alert and incident. Critical knowledge is retained, even after incidents close or engineers depart. Preventive fixes, including observability config improvements and missing regression test cases, are auto generated when an incident is resolved. The end result is engineers get the time needed for proactive work.
Finally, we built the governance layer that early tools ignored. We explicitly built for early security sign-off. Our agents are designed to resolve every governance concern by incorporating controls from the ground up:
Constrained: Restricted by tool allowlists/denylists.
Rate-limited: To prevent unbounded queries from hitting production.
Transparent: Providing a full audit trail of every reasoning step for security and compliance.
If you are an SRE who has been burned by this category, we would rather show you than pitch you. Book a personalized demo today.
