
Most enterprises measure one incident metric, if they measure anything at all. And that is Mean Time To Recovery (MTTR). It is treated as the holy grail because it is part of DORA, and also because leadership wants a single number to point at when they talk about reliability. A smaller set of more mature organizations shift the conversation left and also track Mean Time To Detection (MTTD), recognizing that the sooner you detect a production issue the sooner you can recover. A vanishingly small number track anything beyond that.
Then there is a third metric that nobody measures, because until recently it was not measurable in any practical way. Call it Mean Time To Prevention (MTTP), the time from incident mitigation to shipping the preventive fix that ensures the same underlying cause cannot produce another incident on the same service. MTTP was always conceptually obvious. Tracking it was pointless because shipping preventive fixes competed with the feature roadmap for engineering capacity, and the feature roadmap always won.
This post argues two things. First, the MTTR and MTTD numbers on your dashboard today are incorrect, because no matter what your definitions say, the actual timestamps are produced by exhausted engineers exercising judgment under pressure. Second, AI SRE agents, working alongside coding agents, can produce all three numbers honestly, and in doing so put the organization in a self-improving loop where every incident makes the next one less likely.
Textbook vs Real World Example
Start with the example. A new deploy introduces a memory leak. The first monitor fires at 02:00. The on-call gets paged, acknowledges at 02:10, and starts investigating. They identify the bad deploy and roll it back at 02:30. Error rates return to baseline at 02:35.

So MTTD is 10 minutes, the gap between the alert firing and the on-call engaging. MTTR begins after detection and runs 25 minutes, from acknowledgment to customer impact ending. Clean numbers. A developer patches the underlying bug three days later, work that no clock has ever measured. Standard practice.
Now run the same incident through a real enterprise.
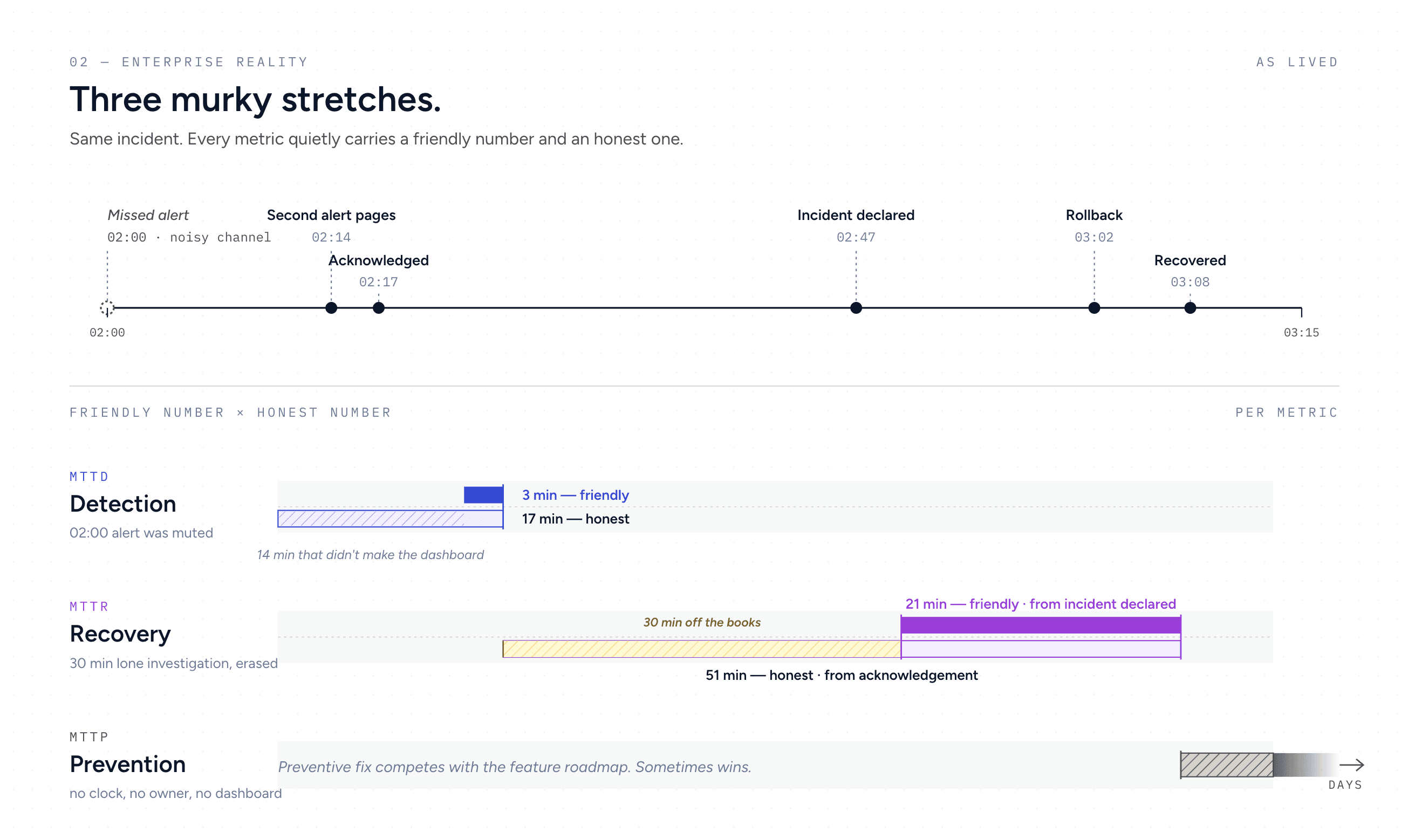
The first monitor fires at 02:00 into a channel nobody watches overnight. A second monitor pages the on-call at 02:14. They acknowledge at 02:17 and spend the next thirty minutes investigating on their own. They check a few dashboards, rule out two hypotheses, ping a teammate, and gradually conclude this is a real customer-impacting problem. At 02:47 they formally declare the incident. They roll back at 03:02 and the SLI returns to baseline at 03:08.
What is MTTD? 3 minutes if you start from the second alert, 17 if you count the missed first alert as the real detection failure. What is MTTR? 21 minutes if you start the clock at incident declaration, 51 if you start it at acknowledgment. Most teams pick the friendlier number. Most teams start MTTR at incident declaration, which silently erases the thirty minutes the on-call spent investigating alone before they were sure enough to call it.
These should have been high-precision measurements, but in reality they are compromises. MTTD and MTTR look like timestamp differences but behave like judgment calls. At enterprise scale, four ambiguities hurt the integrity of the numbers.
When the clock starts. A monitor fires into a channel nobody watches. A second alert pages the on-call. The on-call spends thirty minutes investigating on their own. The incident is formally declared. Any of these can be called detection or the start of response, and different teams pick differently.
When the clock stops. The SLI returning to baseline, the page clearing, the ticket closing, the postmortem completing are four different events. Most teams collapse them into one timestamp.
Which incidents get counted. A SEV2 reclassified to SEV3 mid-incident disappears from SEV2 numbers. Alerts mitigated before incidents get declared never get accounted for if MTTR is the only metric measured. Incidents discovered during postmortems of other incidents rarely get counted retroactively.
Aggregation across teams and services. A single org-wide MTTR averages a payments outage and a batch job delay into one number that describes neither.
Why all these ambiguities exist
Because we left incident measurement to people who are already drowning.
An on-call engineer woken at 02:14 is not going to log a precise detection timestamp, then a precise acknowledgment timestamp, then a precise "I started investigating in earnest" timestamp, then a precise mitigation timestamp. They are going to fix the problem, type a few notes into Slack, close the ticket, and try to get back to sleep. Whatever timestamps end up in the system are reconstructed later, often by the same exhausted engineer, or by someone else doing it from memory or from a fragmented Slack thread.
Then the metric gets attached to a dashboard. Then the dashboard gets attached to a target. Then the timestamps start drifting toward whichever interpretation makes the number look better. None of this is malice.
Every fix that relies on stricter engineer discipline eventually fails for the same reason. There is not enough discipline available in an organization where the people producing the data are also the people running the incidents.
The solution: AI SRE agents record the timestamps
MTTR and MTTD stay as defined. What changes is who records the data and who runs the lifecycle. An always-on agent watching the same telemetry as the engineer on-call does not have a channel it forgets to check. It does not spend thirty minutes investigating quietly before declaring an incident, because the moment it begins investigating, the timestamp is recorded. It does not need to reconstruct a Slack thread later to produce a postmortem. Every event in the lifecycle has a machine signal behind it.
That alone closes three of the four ambiguities. Detection becomes the moment a monitor crosses a threshold and the agent begins acting on it. The investigation window becomes visible instead of remaining hidden. Mitigation becomes the moment the SLI returns to baseline, not the moment a tired engineer closes an incident.
Then MTTP becomes measurable. SRE agents collaborating with coding agents remove the bottleneck that made MTTP impossible to track. The SRE agent that handled the incident knows the root cause and the affected code paths. The coding agent picks up that context, drafts the preventive fix, and ships it through the normal review process. The engineering capacity that used to be the constraint stops being one. MTTP becomes a real number, measurable per incident, reducible quarter over quarter, and visible alongside MTTR and MTTD on the same dashboard.
The self-improving loop
This is where the three numbers start working together, as a complete picture of incident handling that no enterprise has been able to see before.
Real MTTD tells you whether your detection coverage is actually improving, or whether the number is drifting because alerts got tuned later.
Real MTTR tells you whether your response is actually faster, or whether the clock is starting later.
Measurable MTTP tells you whether the work that prevents the next incident is actually getting done, or whether prevention is still losing every quarter to the feature roadmap.
Each number measures a distinct phase. Detection, mitigation, prevention. Together they cover the full lifecycle of an incident from the moment something went wrong to the moment it can no longer go wrong the same way again. Improving one in isolation has limited value.
A team with great MTTR but poor MTTP is fast at firefighting and slow at preventing fires, and the same incidents keep coming back.
A team with great MTTD but poor MTTR notices problems quickly and then takes hours to fix them.
A team with great MTTP on a small population of incidents while MTTD silently misses half of them is only preventing the incidents it knows about.
The loop closes when all three numbers are produced correctly and trended together. Every incident shrinks the next MTTD because detection gaps get fixed. Every incident shrinks the next MTTR because the response pattern is reused. Every incident shrinks the next MTTP because the preventive fix lands and the underlying class of bug is gone. The organization gets steadily better at all three, and the dashboard reflects what is actually happening.
Key takeaway
The math behind MTTR and MTTD has always been trivial. The hard part has been that an incident in a large organization is a social event, and any number put on it has to factor in how exhausted people actually work. As long as the timestamps are produced by engineers, the numbers will keep drifting toward whatever interpretation looks simplest. As long as preventive work competes with the feature roadmap, MTTP will keep being a metric nobody publishes.
Agents that run the incident lifecycle end to end change both conditions. The clocks run on machine signals. The investigation window becomes visible. Prevention becomes an executable instead of an aspiration. The dashboard starts matching the reality on the ground.
This is the thesis behind Autoheal. An always-on AI SRE agent that takes the alert through investigation and mitigation, then collaborates with coding agents on the preventive fix. Real MTTR, real MTTD, and a real MTTP for the first time, produced as a byproduct of the work itself.
SREs are now free to practice their craft. An agent that takes the alert all the way to mitigation, then hands off to a coding agent for prevention, is also reducing the load on the engineers who used to record the timestamps under duress. The on-call who is not paged at 02:14 for an issue the agent already mitigated is the on-call who has the bandwidth tomorrow to review the preventive fix the coding agent drafted. Lower MTTR and lower MTTP start to compound with every rotation.
