The Case Against Tokenmaxxing
Enterprises want outcomemaxxing from purpose-built application-layer AI agents that maximize outcomes per token.

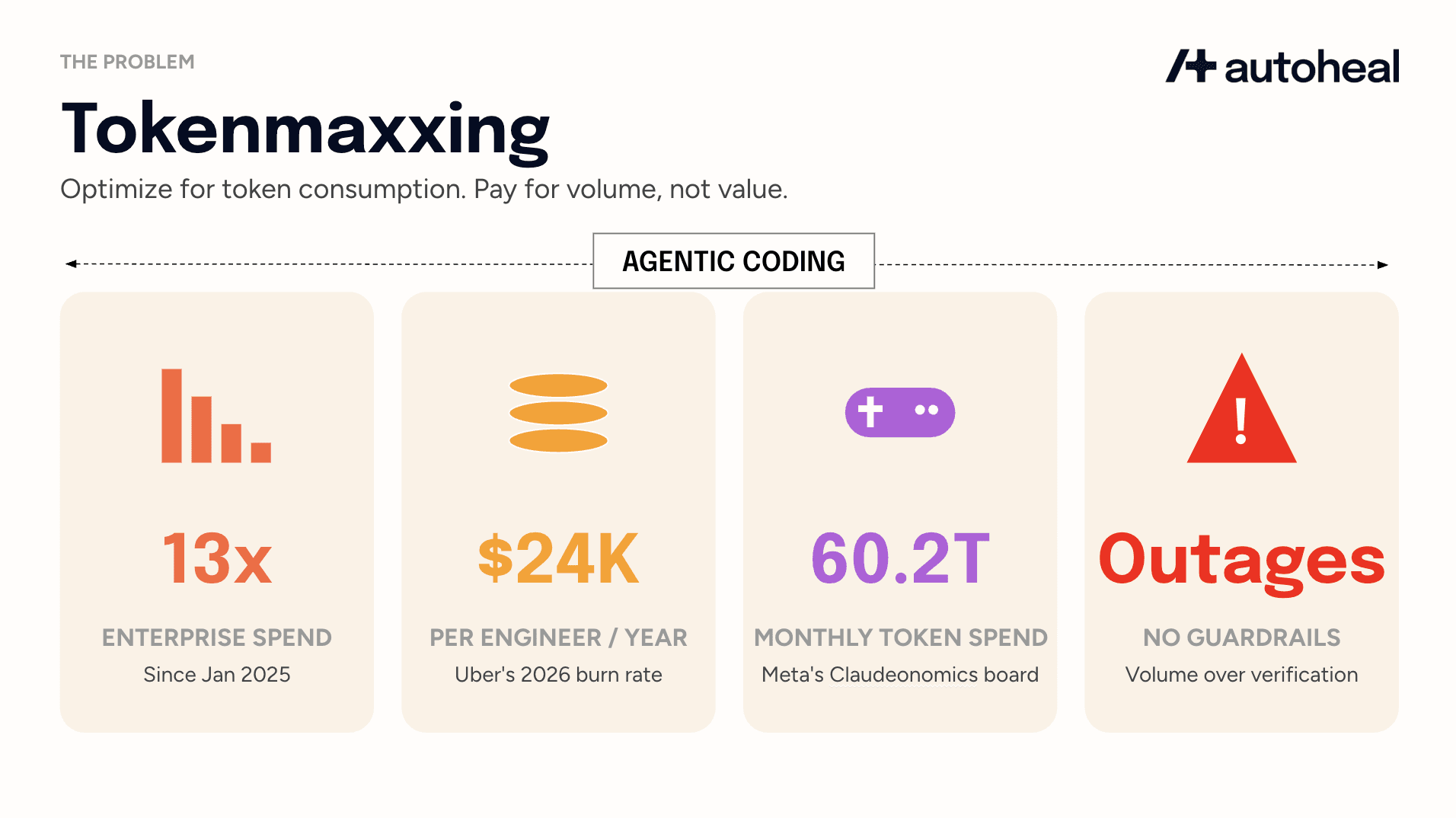
Enterprise token spend is up 13x since January 2025, according to Ramp’s enterprise tracking data. PwC's April 2026 AI Performance study found 74% of AI's value is captured by just 20% of companies while 80% have little to show for it. Model companies are celebrating. Enterprise leaders are not, because this massive spend is often for volume and complexity, not measurable business value.
In practice, tokenmaxxing is the strategy of prioritizing AI token consumption metrics (often through gamification or mandates) as the primary proxy for AI productivity regardless of the business outcome achieved. In reality, tokenmaxxing is a sales and marketing strategy designed to benefit only two groups: the model companies selling the tokens and the firms trying to pump their valuations through “AI nativeness”. Klarna is the canonical example, having paused hiring on the grounds that AI was replacing customer service agents, then quietly resuming engineering hires after its valuation fell by nearly 70%. If you are a traditional enterprise focused on measurable ROI, this trend is working against you. We will refer to the alternative as outcomemaxxing: maximizing measured business outcomes per token consumed.
The case for tokenmaxxing rests entirely on coding
Model providers base the entire tokenmaxxing narrative on one specific use case: a developer synchronously prompting an AI agent to code and test. A larger context window for coding that inherently consumes more tokens enables sophisticated actions beyond generating code blocks, supporting superior reasoning, planning, and detection of cross-repository issues. This full view allows AI agents to perform complex, global refactoring, enforce high-level compliance, and ensure data integrity across an entire pull request or project scope.
Model providers are now extrapolating to other use cases beyond coding. This consumption was never priced at cost. Subsidized per-developer fees for plans like Anthropic Team and GitHub Copilot Pro offered capacity far exceeding their subscription price. On the other hand, API access has always been billed at full market rates without a subsidy. The flat-fee plans are now catching up to that reality.
One consultancy noted the $200 Claude Max plan is essentially the same as $2708 in API credits. Anthropic began removing bundled tokens from enterprise deals in November 2025, and by April 2026 had moved enterprise customers to a $20-per-seat-per-month base fee with all token usage billed at standard API rates on top. This is a massive shift that Redress Compliance estimates could triple bills for some customers. Bundled-allowance “standard” and “premium” seats are now labeled legacy and unavailable on new Enterprise contracts.
GitHub Copilot announced the same direction last week, pausing new Pro, Pro+, and student signups on April 20, introducing weekly token caps, pulling Opus-family models from Pro (and Opus 4.5 and 4.6 from Pro+). It confirmed yesterday that all plans will transition to usage-based billing on June 1, 2026 as weekly Copilot operating costs nearly doubled since January.
The simultaneous removal of subsidized pricing and the tokenmaxxing mandate has created an immediate and visible budget crisis, leading to the following high-profile operational risks at major enterprises:
Uber burned through its entire 2026 AI budget in just three months, driven by Claude Code adoption that doubled month-over-month after its December 2025 rollout, with per-engineer monthly API costs running between $500 and $2,000. If sustained, this represents a potential annual cost of up to $24,000 per engineer. Uber’s CTO said the company is back to the drawing board on AI budgeting.
Meta's internal Claudeonomics leaderboard, which tracked 85,000 employees consuming 60.2 trillion tokens monthly (the equivalent of a $900M market value), was shut down after scrutiny. This gamification incentivized prompt complexity over simple solutions, turning AI into a high-cost volume game that also serves as free training data for model vendors.
A Microsoft engineer gamed internal AI dashboards by burning tokens on redundant questions and unnecessary features to avoid being seen as an AI laggard.
Salesforce formalized the pressure, mandating minimum spend of $100 monthly on Claude Code and $70 on Cursor. Results are not published yet, but the pattern is clear: when spending becomes the primary metric, engineers simply calibrate to the average, resulting in real costs without real outcomes.
Defenders of tokenmaxxing make a real point. Token volume is a useful adoption signal in year one especially for workflows like coding where the business impact is not immediately measurable. Reid Hoffman has argued for tracking it on a dashboard for that reason. The problem is treating an early-adoption indicator as the primary KPI in year two and beyond. At that point token spend stops measuring how much AI you have and starts measuring how much money you are sending to model vendors per unit of work. Adoption velocity does not pay the cloud bill, and the CFOs who approved the year-one experiment are now asking what they got for it.
Lastly, tokenmaxxing in the coding phase creates operational debt and failure modes that production teams must manage without a corresponding tokenmaxxed budget.
Agentic production engineering requires full coverage
The expectation enterprises bring to agentic alert/incident response in production is specific and demanding: triage every alert, investigate every incident, propose a mitigating fix every time, and execute a postmortem for every resolved incident.
Enterprises demand full coverage because only total visibility can distinguish critical signals from routine noise that might precede an outage. They reasonably expect AI to outperform a sleep-deprived human at 2 AM triage, but they refuse to pay "tokenmaxxed" rates for it. The burden of cost efficiency for comprehensive incident management falls solely on the agent provider. Success requires specialized, purpose-built workflows that minimize tokens per outcome, which is the defining innovation of the application layer.
The enterprise budget reality demands outcomemaxxing
Model companies claim tokenmaxxing is budget-neutral via labor arbitrage, assuming payroll savings offset token costs. However, most enterprises aren’t reducing headcount. They invested in AI for increased delivery, not team shrinkage. CFOs view token spend as a new, un-offset expense.
When applied to the production operations world, the only rational evaluation framework is outcomemaxxing. Here token count is not the metric. The metrics that matter are how many alerts got triaged, how many incidents got an accurate root cause, how many postmortems were completed on time, and how much MTTD, MTTR, and postmortem RCA time actually fell.

Kishen Patel, VC at Greycroft, wrote recently about how value in AI will shift over time toward the application layer and away from the model and infrastructure layer where model companies hold pricing power. He notes that enterprises want max outcomes at the least tokens possible which is aligned with application layer companies who win those enterprises as customers by minimizing tokens per outcome via purpose-built agentic workflows.
What this means for enterprises evaluating AI for production engineering
AI for production engineering splits into two options: buy application-layer AI purpose-built for production engineering, or build your own harness on top of either a model provider like AWS Bedrock, Claude Code SDK, OpenAI Codex or on top of a coding agent platform like that of Cursor or Devin.
Application-layer AI companies like Autoheal for SRE, Sierra for Customer Service, Harvey for Legal are on the outcomemaxxing side by design. Our value depends entirely on delivering measurable outcomes at a cost structure that makes comprehensive coverage sustainable. Specifically, Autoheal succeeds only when customer’s alert-driven MTTD and incident MTTR gets reduced.
Model provider alternatives such as developer SDKs and managed agent platforms facilitate homegrown AI engineering but are inherently "tokenmaxxed." Providers profit from every token consumed during development, testing, and operations, leaving the responsibility for maximizing outcomes per token to the engineers. This model favors the vendor even if it fails to improve incident triage or resolution. Despite the convenience of a single-vendor relationship, poorly engineered harnesses can result in costs far exceeding those of purpose-built tools.
Enterprises making a build-versus-buy decision must decide which side they are on. By choosing Autoheal, you are not just choosing a vendor; you are choosing an outcomemaxxing partner dedicated to your business goals. This ensures your comprehensive production coverage is not only technically possible, but financially sustainable.
