Why Your Coding Agent Can't Handle a P1 Incident
A Production Engineering task involves 10x more services, 10x more tools, 10x more people, and 10x more time urgency than a Coding task, without any publicly available data to train via Reinforcement Learning.

Jeff & Claude Code
You are Jeff. You are an awesome engineer. Claude Code has enabled you to build your latest feature in days instead of months. You update your CLAUDE.md with all the annoying things in your dev loop — environment variables, test harness setup. You write a skill to review code for concurrency and injection because you care about it the most in your team. You build a claude -p chatbot connected with Slack, GitHub, Notion MCP servers that answers questions on your team's Slack channel. Everyone loves it. You are invited to join the AI tiger team at Topcorp, your mission-driven Fortune 500 employer, to build agents for employee productivity.
The on-call week
Your on-call week comes around.
There are too many noisy alerts. So you write a scheduled Claude Cowork task that clusters alerts as they come. Claude queries to your logs MCP server are timing out, so you write a query-logs skill with proper filters. Log queries exceed the 25k tool response limit, so you update the skill to dump logs to tmp/ and search locally. You hope Security doesn't find out.
Meanwhile, your Claude Code debug sessions are piling up — each one stuck in the "Now, I understand the problem"/ "Yes, you are right!" loop, waiting for your adversarial questioning.
After 5 million tokens, you isolate the suspect log line. The root cause appears to be an assumption made by a downstream service — but the engineer who built it left last year. You git blame your way to the only remaining committer who vaguely remembers a related incident from two years ago. You MCP-search through Jira and find a ticket with a one-line root cause that's suggestive but not conclusive.
Collaborating with Sanjay
The ticket links to a Notion runbook that queries a production database only a few platform engineers can access. One of them, Sanjay, gets on a call. The runbook is outdated, so Sanjay uses Claude Code to regenerate the commands. Your hypothesis is invalidated. You ask Sanjay to generalize his script for other SREs and write a skill to keep it updated. He promises next week. He has his own fires.
The Prodigy vision
On your hike Sunday, exhausted, the architecture clicks. You need a root-cause-reviewer skill to break the "yes, you are right" loop. A mitigation-reviewer skill for writing commands to infrastructure. Evals, or you'll someday cause an Amazon-size 13-hour outage. Having worked on ML problems before, you realize the evals need continuous upgrades — a day every week for the next year, at least. You call the vision "Prodigy." It's significant work. Weeks of your dedicated attention. Maybe Sanjay's too.
What your on-call week revealed
If you think of your software organization as a factory, coding and production engineering are on entirely separate floors — different objective functions, different skills, different tools, different people. Your coding agent was built for one floor. Your on-call week just showed you a completely different one.

Coding is a "single-player" game in a bounded, structured world. Production is a "multiplayer" war room where the state of the world is distributed across a dozen fragmented systems.
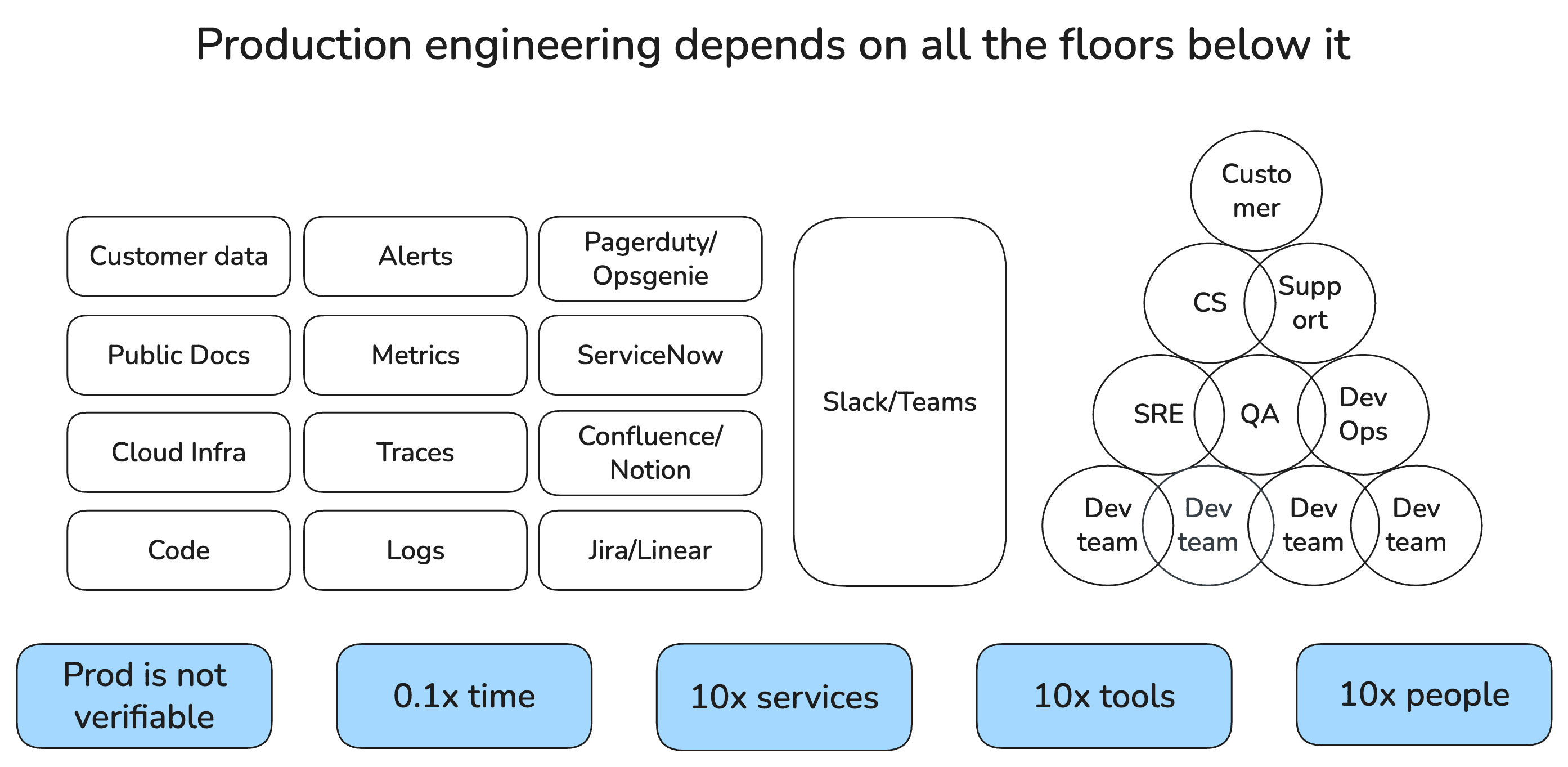
Each of those 10x multipliers compounds — scope, people, and tools don't add, they multiply into a 1000x search space. How do you efficiently search through it? How do you capture the data to train on it?
If Topcorp were a ten-person team with five microservices, modern observability, and zero alert noise, Claude Code might actually be sufficient. Your "institutional knowledge" would just be ten people in a room. But Topcorp isn't that. At scale, the leap from coding agent to production engineering agent requires a structural rebuild. You, Sanjay, and every engineer who's been woken up at 3 AM need serious engineering across context systems, traditional ML, and Reinforcement Learning.
What you need to build on top of coding agents
Back at your desk on Monday, you start writing the spec for Prodigy. Here's what you realize you actually need.
1. The Production Context Graph
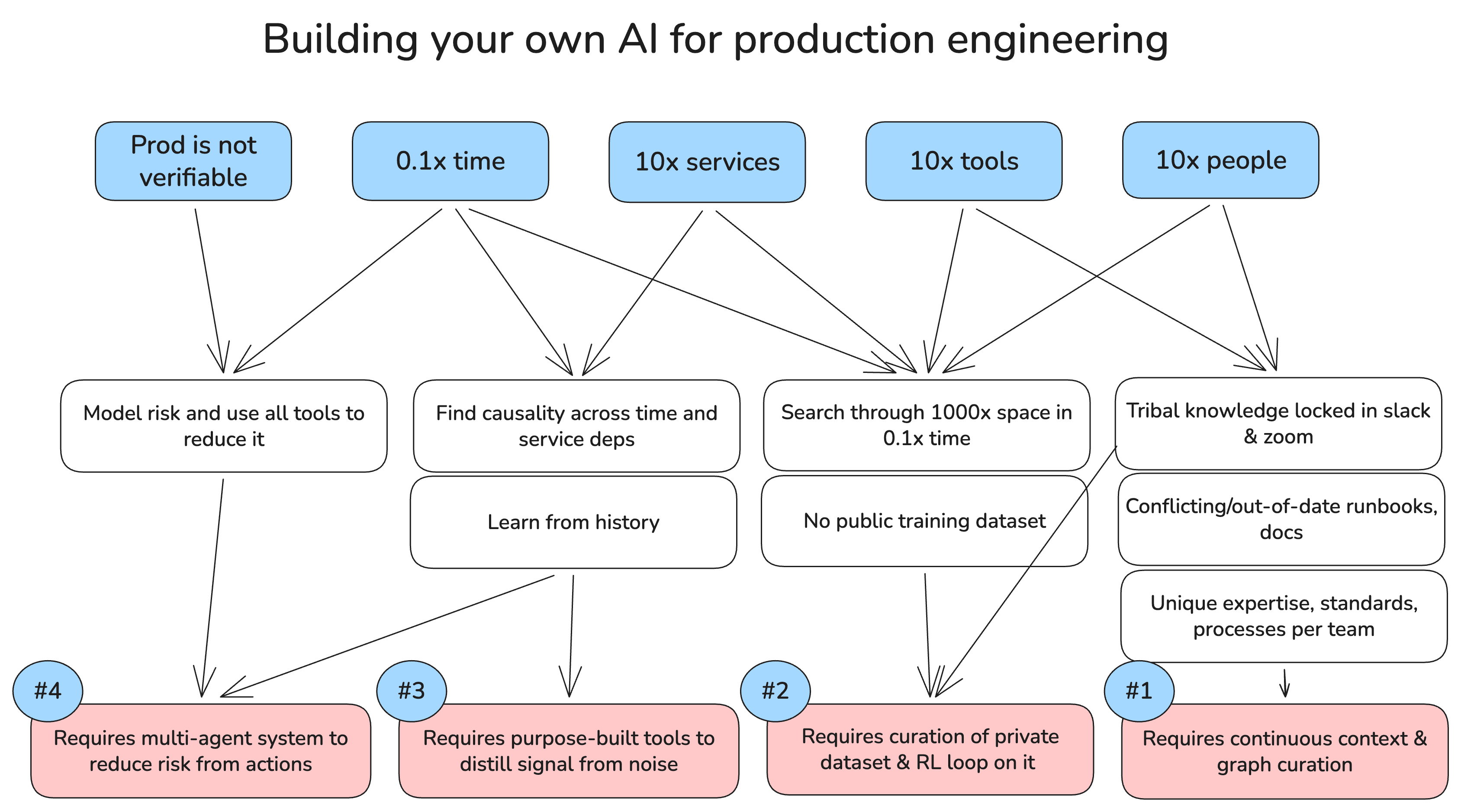
Production knowledge is scattered, tribal, and evaporates every time someone leaves. Prodigy needs to do four things:
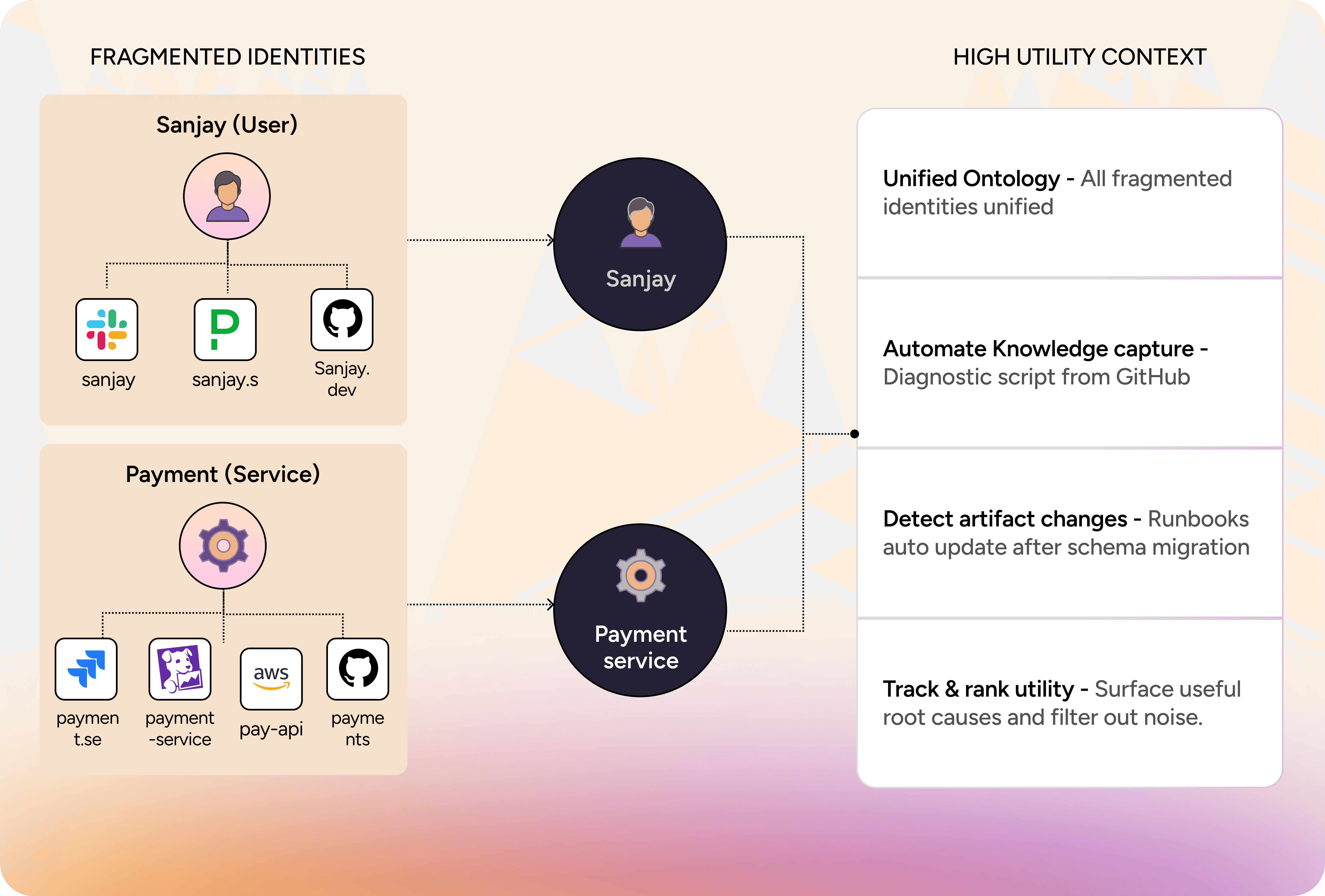
a) Join fragmented identities. The same service had four different names across Datadog, Jira, AWS, and code. Sanjay had three. Prodigy needs a shared ontology that resolves these into single entities across every tool in Topcorp's stack.
b) Capture knowledge as it's created. Sanjay promised to generalize his diagnostic script. He won't — he has his own fires. Prodigy needs to capture scripts and decision traces from incidents automatically, so the next on-call doesn't start from scratch.
c) Track changes across the organization. The runbook was outdated because someone migrated the database schema three months ago and nobody updated Notion. Prodigy needs to detect changes and update dependent artifacts so no runbook is stale at 3 AM.
d) Learn what's actually useful. The Jira ticket with the one-line root cause was gold; the 200 Slack messages asking "any update?" were noise. Prodigy needs to track utility so search results surface what mattered.
2. The RL Loop
Remember your debugging session? You queried Splunk, then checked K8s deployment status, then read Slack history, then found a runbook, then asked Sanjay to run a diagnostic against the production database. That was your sequence — an experienced engineer's intuition about which tool to reach for next. Now imagine teaching an agent to make those same choices across every possible incident. The combinatorics are massive compared to a coding agent that just reads, writes, and runs code locally. And repeatedly querying observability APIs is extremely costly and slow. This is a classic search problem where you need a Reinforcement Learning (RL) training loop.
But there's no public training data. Production has no public dataset to train on. There is no "GitHub for Incident Reports." Topcorp's most valuable debugging knowledge lives in Sanjay's head and a two-year-old Jira ticket with a one-line root cause. Every organization must build its own private RL loop on its own failures, remediations, root causes and what we call decision traces.
So you have to build your own dataset. This is why Prodigy can't be a weekend project. You need to instrument incident response across the 10x people — listening in and assisting them across Slack, Teams, Zoom, and ticketing systems during real incidents like the one you just fought. You extract "decision traces" — moments where new information proved instrumental. Remember when Sanjay's runbook invalidated your hypothesis? That pivot is a decision trace. You train the agent in simulation against recorded traces, penalizing inefficient queries and rewarding the fastest route to resolution
3. The ML Tooling
If you'd pointed Claude Code at your alert channel Monday morning, it would have seen the latency spike in Service A and started debugging Service A's code. But the real cause was four layers deep: a rolling database migration exhausted the connection pool in Service E, which cascaded up. A coding agent looking at a snapshot misses the temporal chain.
Connect Claude directly to the alert stream and it will chase every blip, burning a million dollars in API costs in a day. Before Prodigy can act, traditional ML needs to do what you did manually with your cron script, but better. Purpose-built models can group related alerts into incidents, infer anomalous inflection points across time and filter out non-actionable noise. This ensures the expensive LLM agent only engages on true signals — not transient retry storms. Building these tools is fast with Claude Code, but the training-inference loop needs continuous iteration. Every new service Topcorp deploys changes the topology, and every iteration cycle is time away from Topcorp's core business.
4. The Verification Problem
In coding, a bad suggestion costs five minutes — the tests catch it and you revert. In production, if Prodigy suggests restarting Service E to "fix" the connection pool exhaustion, and the real cause is the upstream migration, that restart drops customer transactions for ten minutes. There is no compiler, and "undo" can take thirty minutes to propagate.
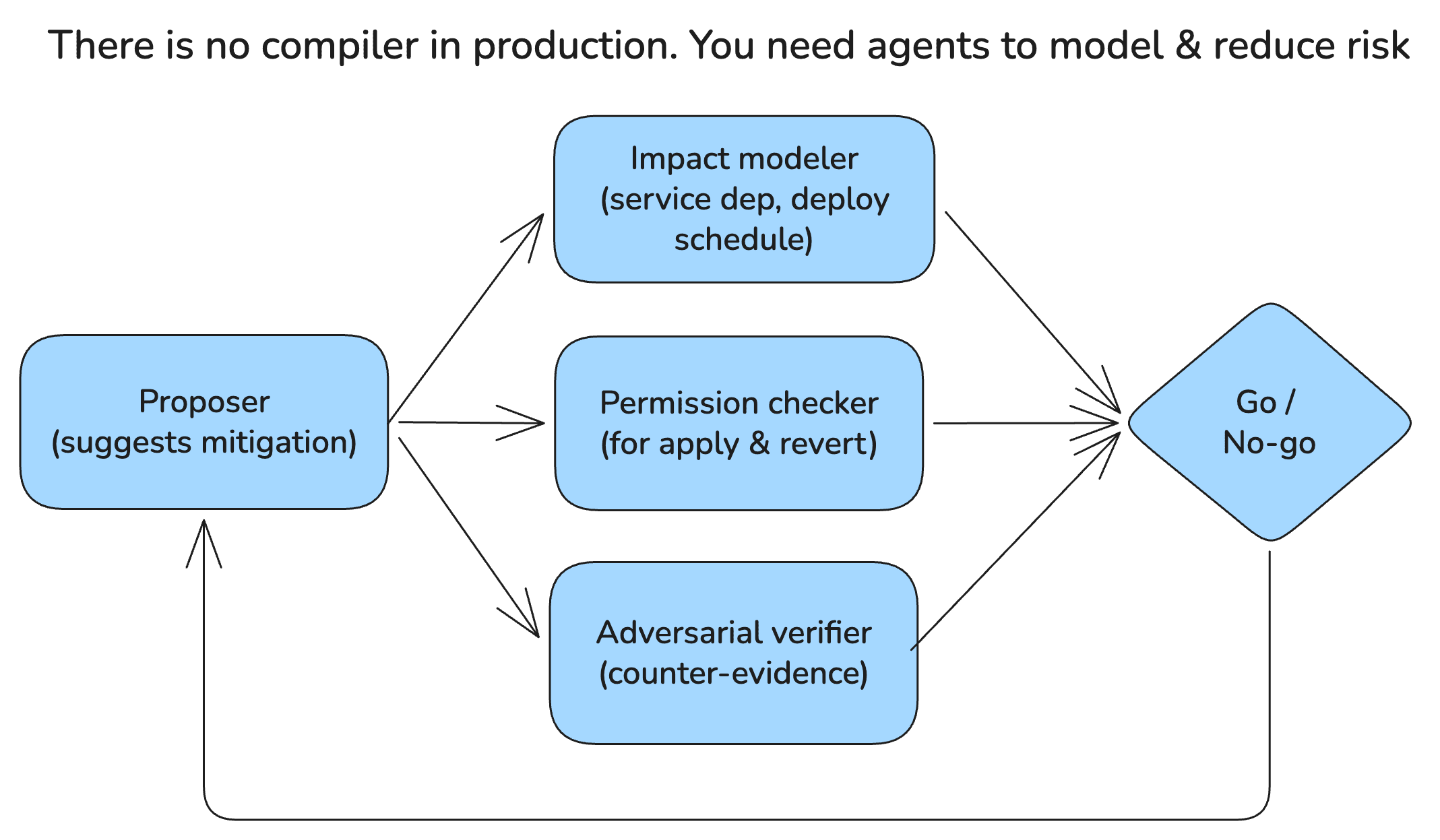
Prodigy can't be one confident voice. You need a team of agents that argue: one suggests the mitigation, a second models the blast radius, a third checks scheduled deployments, a fourth validates permissions and revert capability, and a fifth argues adversarially that the action might break something else. If any check fails, the action is blocked. Once deployed, you evaluate continuously on real data and iterate.
The build-or-buy moment
Building Prodigy is months of dedicated engineering across RL, ML, and context systems. Every week you and Sanjay spend on it is a week away from Topcorp's core product. And until it's production-grade, a confident-but-wrong AI agent at 3 AM is a severe liability, not an asset.
At Autoheal, we've done the engineering that Jeff is dreaming about. The Production Context Graph that joins Sanjay's six different usernames. The causal reasoning engine that traces a 2:05 AM spike back to a 1:00 AM migration. The private RL loop trained on real incident decision traces — not public GitHub data. We built this so that engineers like Jeff and Sanjay don't have to spend the next year building it themselves.
Want to see how it handles a real cascading failure? Book a demo with us.
