The Path to Self-Driving Production
A five-level framework for SRE leaders

In the last couple months I have noticed a change in SRE & platform leaders. Many believe they are already using AI for production and therefore are already at their final destination.
A team where the on-call engineer pastes a few production log lines into their local Claude Code or Amazon Q Dev Assistant during a P1 incident is not in the same category as a team where agents autonomously correlates observability, cloud, CI/CD, code, query context from a shared production graph, propose mitigations, and execute bounded actions with engineer approval. However, both teams tell their CTO that they are using AI for incident response. This simplistic framing of “using AI or not” is misleading. It lets a tool that summarizes logs compete on the same scale as an agentic system that resolves them end-to-end.
The autonomous vehicle industry hit the same problem. Then came standardized autonomous driving levels that forced precision and established the clarity that neither cruise control nor lane keeping was autonomy. Conversations got sharper, regulation got clearer, and buyers stopped getting confused. This post proposes a similar framework for agentic SRE.
Incident response is not the same as alert response
Before the framework, note that there are two distinct workloads inside production reliability that even SREs conflate, because the pre-AI era never forced the distinction.
Incident response handles declared P1s with unambiguous signal: investigate, decide, mitigate, recover. The metric is Mean Time To Restore (MTTR). Most “AI SRE” marketing focuses here because it is the more immediate value-based outcome for SREs.
Alert response handles P2/P3 alerts that arrive in high volume but low signal. Most are noise, some are early P1 warnings. The metric is Mean Time To Detect (MTTD). Engineers cannot do this manually at modern alert volume. Teams either suffer from alert fatigue or set thresholds so high that P1 is the only thing they hear about.
Value from agentic alert response is at least as high as that from agentic incident response. A P2 caught before becoming a P1 is an incident that was prevented. Most AI SRE products optimize for MTTR and undervalue MTTD. Organizations should ask vendors about both workloads. As we will see in the maturity framework, hard tests at each level cover both.
The four-question lens
Ann Miura-Ko from Floodgate recently posted what every executive should be asking their team about AI adoption. Her four-question lens applies to SRE leaders too:
What can the AI see? Is production legible to an agent, or does context live in tribal knowledge, stale runbooks, and disconnected SaaS tools?
What can the AI do? Only summarize what engineers wrote down, or orchestrate systems of record (rollback, restart, scale, open a PR, ship a hotfix)?
Who can extend the system? Only SREs, or can app dev teams author service-specific agents, runbooks, and skills?
How has on-call actually changed? Same shape as 2024 with better autocomplete, or has the operating model itself shifted?
Using the above lens, here is a five-level maturity framework for SRE leaders to self-assess where they currently are, identify the next intervention, and evaluate vendor claims against a consistent yardstick.
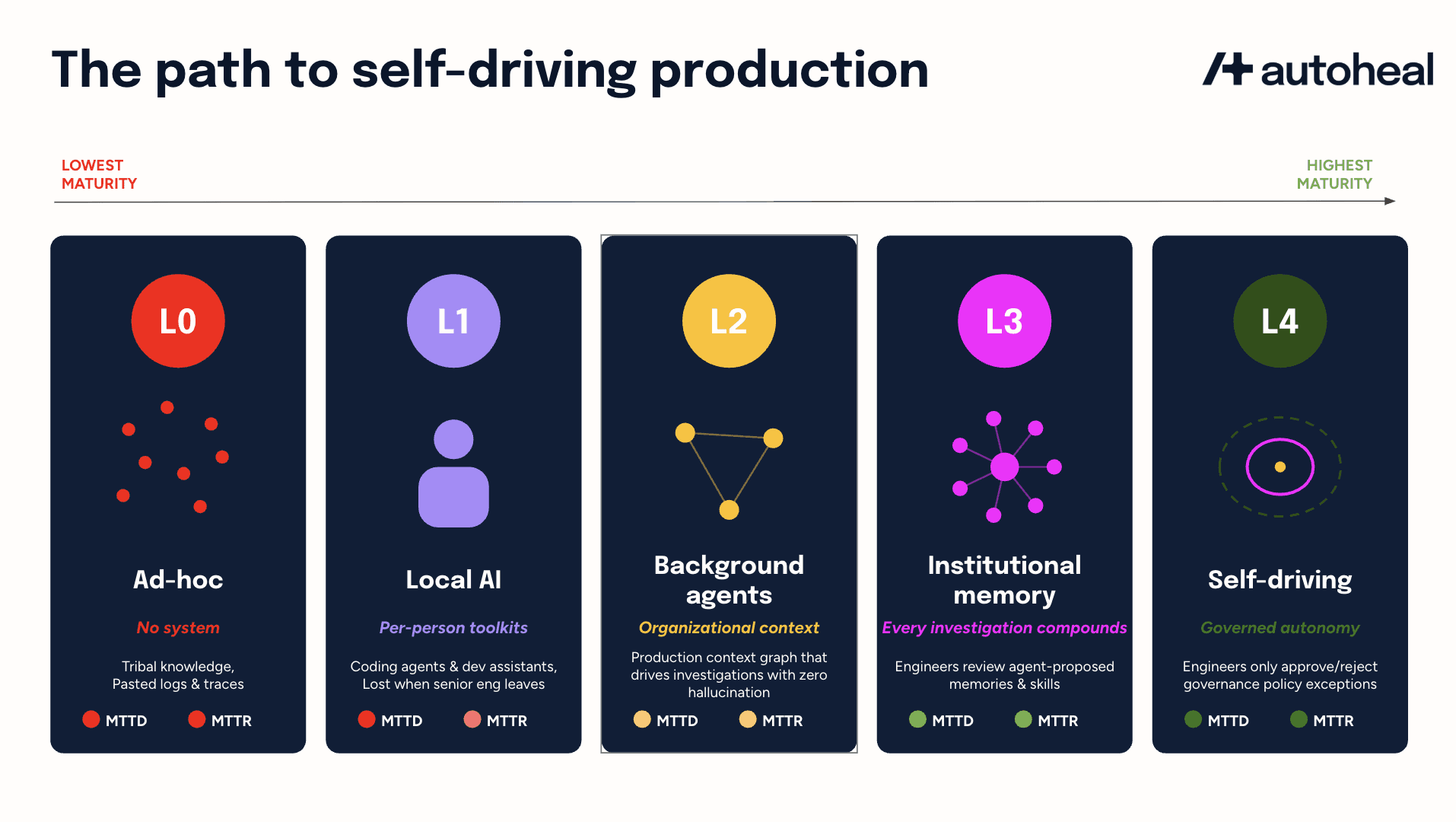
L0: Ad-hoc
What can the AI see? Nothing structured. Production state lives in dashboards no agent reads, stale runbooks in Confluence that no agent reads or updates. Knowledge is concentrated in the heads of the two longest-tenured engineers.
What can the AI do? Nothing of consequence. Engineers paste stack traces into GitHub Copilot or ChatGPT and get back plausible-looking explanations that may or may not be accurate.
Who can extend the system? No one. There is no system, just individuals using individual tools.
How has on-call changed? It has not. MTTD and MTTR are both poor with no system to move either.
Hard test (alert response): Any system that decides which P2/P3 alerts deserve attention or is detection just senior-engineer intuition?
Hard test (incident response): Any recurring part of incident response that completes without an engineer typing every query?
L0 is the default state. Most engineering orgs are still here even when leadership believes otherwise.
L1: Local AI
What can the AI see? Whatever each engineer feeds into their own toolkit on their local machine, powered by coding agents like Claude Code or Cursor or even developer assistants like Amazon Q. Saved prompts, scratch files, a private MCP setup pointed at Datadog or Grafana. Visibility is per-person, not per-team.
What can the AI do? Help an individual engineer debug faster. It can generate queries, draft updates, investigate issue classes the engineer has personally tuned for.
Who can extend the system? Each person reinvents independently. The strongest engineer’s workflow is lost if they leave.
How has on-call changed? MTTR improves modestly on issues those individuals encounter. MTTD does not move. The coding agent has no shared visibility or team-level pattern matching. The rotation is unchanged.
Hard test (alert response): Does the team have any system that filters P2/P3 noise or is pattern matching purely individual?
Hard test (incident response): Can a new on-call engineer inherit the previous on-call engineer’s AI workflow on day one without a tribal-knowledge handoff?
L1 lifts individuals, not the engineering organization.
L2: Background agents
This is the focus of current AI SRE products.
What can the AI see? A shared organizational context built and maintained by the SRE team. A production context graph captures service dependencies, ownership by team, deployment history, and troubleshooting runbooks. Systems of record exposed via MCP or CLIs. Production is now legible to agents as a coherent whole. App dev teams show up during specific investigations but are not regular contributors to the context outside those moments
What can the AI do? Agents now auto-instantiate on alerts and incidents, running in "background" mode within ephemeral cloud sandboxes to investigate issues across observability, cloud, CI/CD, and code. Alert response investigations correlate P2/P3 signals with cloud state and deployment history to suppress noise and detect emerging P1s, while incident response investigations perform evidence-backed multi-hypothesis root cause analysis. Agents propose mitigations and can execute operational actions like rollbacks or restarts with engineer approval. Agents must run adversarial verification so investigations stay grounded in evidence rather than plausible-sounding hallucinations.
Who can extend the system? The SRE team only. App dev teams are consumers.
How has on-call changed? MTTD and MTTR move for the first time. Capacity to handle issues expands without proportional headcount. The rotation remains but each shift is more productive. For example, the agent ties a slow drift in P95 latency on the checkout service across three otherwise forgettable P3 alerts to a config change shipped the previous evening, then proposes a rollback the on-call engineer approves before morning traffic peaks. The P1 that would have hit at 9am never gets declared.
Hard test (alert response): Can the agent surface a P1-in-the-making signal from noisy P2/P3 alerts, with enough lead time to act?
Hard test (incident response): Can the agent resolve a P2 end-to-end without an engineer typing the queries or correcting hallucinations?
SRE teams should drive their organizations to be in L2 in the next 6 months. However, they should understand that L2 is one of the milestones on the path to the final destination.
L3: Institutional memory
What can the AI see? The context spans every service in depth because app dev teams are now looped in directly. They approve, edit, and reject memories and skills the agent auto-collects as decision traces from Slack/Teams/Zoom collaboration, and they add their own service-specific skills. The graph is queryable across team boundaries. Agents see the checkout microservice at the same depth as the SRE-owned platform services.
What can the AI do? Agents record decision traces from Slack/Teams/Zoom collaboration between engineers to accelerate identification of novel, complex failures. Each team curates these auto-collected memories and skills (approve, edit, or reject) and authors their own service-specific skills. Incident response also involves each team configuring which mitigations execute autonomously and which require expert engineer approval.
Who can extend the system? Every engineering team. A backend engineer on payments writes an agent skill capturing the three failure modes their service hits most often. Reliability tooling is no longer SRE-exclusive.
How has on-call changed? MTTD and MTTR both drop substantially again. Service-specific signal-to-noise that no central team could build catches emerging P1s that would otherwise have escaped, dropping MTTD. Institutional memory from decision traces and team-authored skills together drop MTTR on novel failures. The SRE team shifts from incident commander to platform steward.
Hard test (alert response): Can a service owner approve, edit, or reject a signal-to-noise memory the agent proposes, AND author their own pattern from scratch, both without filing a ticket with the SRE team?
Hard test (incident response): Can a backend engineer who has never been on-call approve an auto-generated agent skill that improves MTTR for their service?
L3 is hard to achieve if L2 is a weak start, which is why we built Autoheal around the L2-to-L3 jump with our Production Context Graph as the driving force.
L4: Self-driving production
L4 is the final destination that is starting to show up at the model companies like OpenAI and AI-native startups like Ramp where there are “self-driving codebases” already in operation. Traditional enterprises cannot reach L4 today because of high complexity and open security and governance challenges. The shape still matters because it determines what to build toward at L3, just as full self-driving became reachable first for the manufacturers who had already shipped driver assistance.
What can the AI see? The system maintains its own context. Long-running background agents observe production state, deployments, code commits, and observability signals continuously. The system identifies its own gaps and runs investigations to close them before incidents occur.
What can the AI do? Agents operate 24/7. Alert response means the system hunts for emerging issues without waiting for an alert. MTTD approaches zero on learned classes, and the distinction between alert and incident blurs. Incident response means work that once needed an engineer to notice, file, prioritize, and execute now runs as long-lived background workflows within explicit governance, escalating to expert engineers only outside delegated authority.
Who can extend the system? Governance is the primary surface. Engineers review agent's auto generated skills and write governance policies. PMs contribute business context. The Security and Compliance team contributes constraints. The work shifts from detailed specs to allowlists/denylists.
How has on-call changed? MTTD approaches zero and MTTR follows it to the floor. Most of what we call incident response today disappears. Engineers review flagged exceptions, approve actions outside delegated authority, and author governance. Work shifts from first responder to flight director. The dark factory analogy applies: a production environment operating correctly should not require an engineer looking at it all the time.
Hard test (alert response): What P1 did you avoid last quarter because the system caught the precursor unprompted and resolved it before escalation? Something it noticed without being asked.
Hard test (incident response): What important reliability work did the system initiate, prioritize, execute, and learn from last quarter, with no engineer in the loop? If nothing, you are not at L4.
Architectural choices at L2 and L3 determine whether L4 is reachable. A context built for episodic invocation cannot become continuous by adding features. This means a coding-agent foundation cannot become self-driving production no matter how many tokens you throw at it. The path to L4 runs through purpose-built application-layer SRE in L2 and L3.
What this means for cost and ROI
Cost structure changes shape at each level. Leaders need to know which curve they are buying.
At L0 and L1, cost is hidden in senior engineer time absorbed into incident response, flat MTTR, poor MTTD and platform engineers are firefighting instead of implementing production guardrails.
At L2 the context has a price tag. ROI shifts to engineering capacity freed, MTTD reduced and P1 incidents avoided by looking at all alerts as well as MTTR improvement on covered incidents. For most teams this is positive within 2 to 3 quarters. Incidents avoided count is harder to measure and often the larger number; leaders who only track MTTR will systematically undervalue the program.
At L3 the economics look like a developer platform. Done right, cost per service trends down as adoption goes up. Done wrong, agent sprawl outpaces any gains.
At L4 the cost model inverts. Token consumption by continuous background agents grows, and the headline AI bill looks uncomfortable benchmarked against L2. The offset is the work that was previously absorbed by headcount. Price L4 correctly and you pay for outcomes (alerts triaged, incidents resolved, P1s avoided) rather than tokens or headcount.
The deeper discussion across L2-L4 is around tokenmaxxing, where token consumption is treated as the proxy for AI productivity. Tokenmaxxing does not work for the SRE workloads of agentic alert and incident response. Outcomemaxxing is the only viable expectation here. When SRE teams build their own autonomous agents on an LLM or a coding agent SDK, the vendor profits from every token whether or not incidents resolve. The smarter choice is to buy a purpose-built application-layer AI SRE where the vendor outcomemaxxes on MTTR and MTTD going down.
What changes for regulated enterprises
Most engineering frameworks assume a high-growth software company with a permissive GRC posture. What about SRE teams at banks, healthcare providers, insurance companies, and infrastructure platforms, where moving fast on production is structurally hard? The levels still apply but with extra constraints.
At L2, the context has to be auditable from day one. Every action against a system of record needs a tamper-evident log. Read access usually requires data residency and field-level controls. Write access requires a service identity tied to existing change management.
The L2-to-L3 transition is the hardest one in any environment, and in regulated enterprises it has additional requirements. Agent skills authored by app dev teams must be treated as code, managed through the same change-control pipelines as production releases, and traceable under SOC 2 Type II to specific authorizations. Agents can surface regulated data during investigations, which requires explicit governance over who is allowed to see such data. Additionally, US-centric architectures may require adjustments for international data residency.
By the time an enterprise reaches L3 with this infrastructure in place, the L3-to-L4 shift is mostly additional governance work rather than new architecture. Continuous autonomous operation requires explicit, machine-readable governance enforced on every retrieval, with tamper-proof audit trails. Delegated authority and separation of duties already apply, but translating them for agents is real work.
What SRE teams should do next
SRE teams with good observability but no agentic workflows have a clear next step to reach L2: close the agent action loop on a shared production context. Getting from L2 to L3 means turning app dev teams into reviewers of agent-generated skills and memories. The final step is to author agent governance policies for delegated authority to reach L4.
The immediate action item for SRE teams is to use this framework as a yardstick. Run an honest self-assessment while also pressure testing vendor claims against it. The L2-to-L3 jump is where engineering organizations actually change shape, and most teams underestimate what it takes. Get that one right and L4 becomes the logical next step.
